
A Spatial Transformer Network (STN) is a learnable module that can be
Abstract. We propose a generalization of transformer neural network architecture for arbitrary graphs. The original transformer was designed for Natural Language Processing (NLP), which operates.
The Ultimate Guide to Transformer Deep Learning
A graph transformer with four new properties compared to the standard model, which closes the gap between the original transformer, which was designed for the limited case of line graphs, and graph neural networks, that can work with arbitrary graphs. We propose a generalization of transformer neural network architecture for arbitrary graphs.
Graph Transformer Networks Papers With Code
Abstract: We propose a generalization of transformer neural network architecture for arbitrary graphs. The original transformer was designed for Natural Language Processing (NLP), which operates on fully connected graphs representing all connections between the words in a sequence.. We introduce a graph transformer with four new properties.
Transformer as a Graph Neural Network — DGL 1.2 documentation
1. Background. Lets start with the two keywords, Transformers and Graphs, for a background. Transformers. Transformers [1] based neural networks are the most successful architectures for representation learning in Natural Language Processing (NLP) overcoming the bottlenecks of Recurrent Neural Networks (RNNs) caused by the sequential processing.

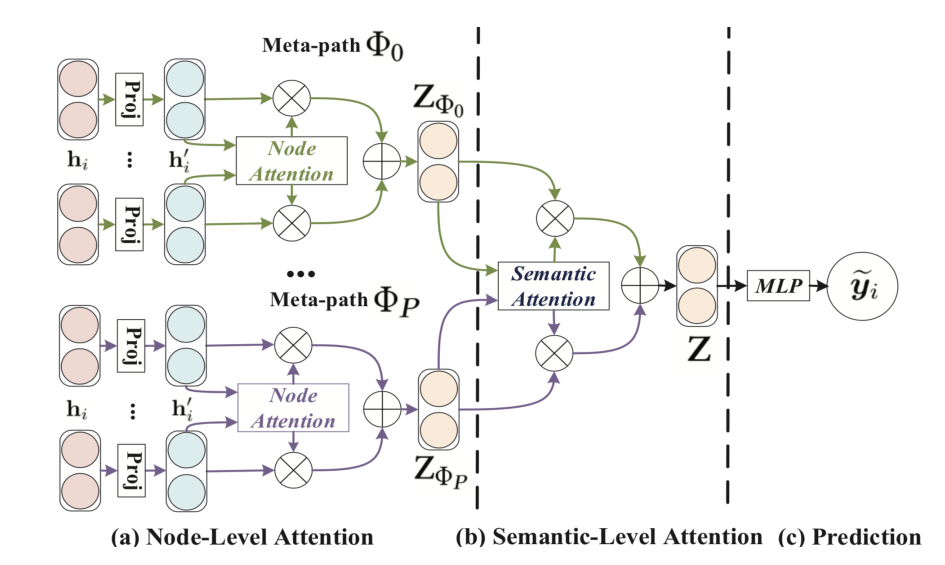
Graph Attention Transformer Network for MultiLabel Image
2. Abstract. 作者提出了一种适用于任意图的transformer神经网络结构的推广方法。. 原始的transformer是建立在全连接的图上,这种结构不能很好地利用图的连通归纳偏置——arbitrary and sparsity,即把transformer推广到任意图结构,且表现较弱,因为图的拓扑结构也很重要.
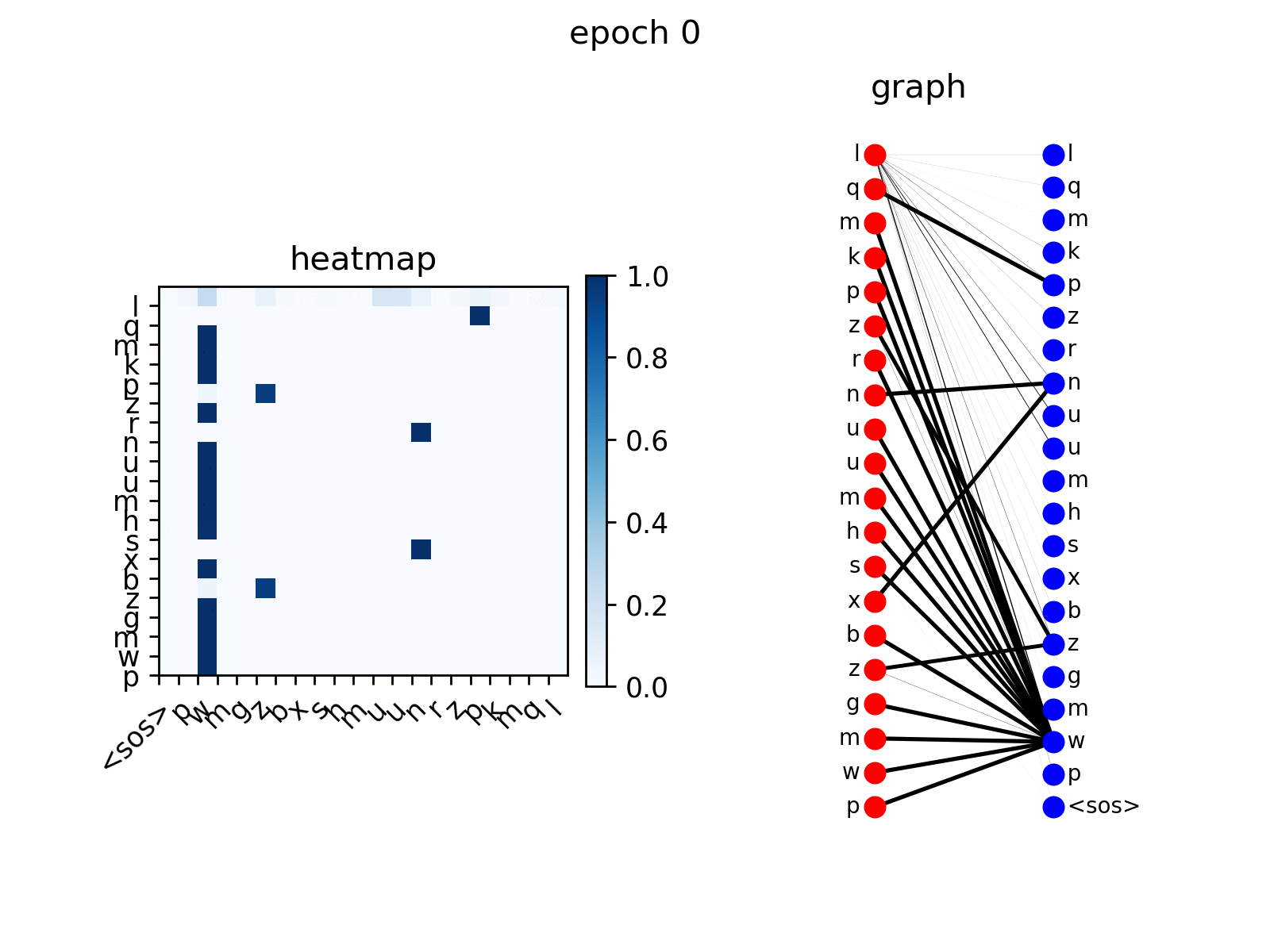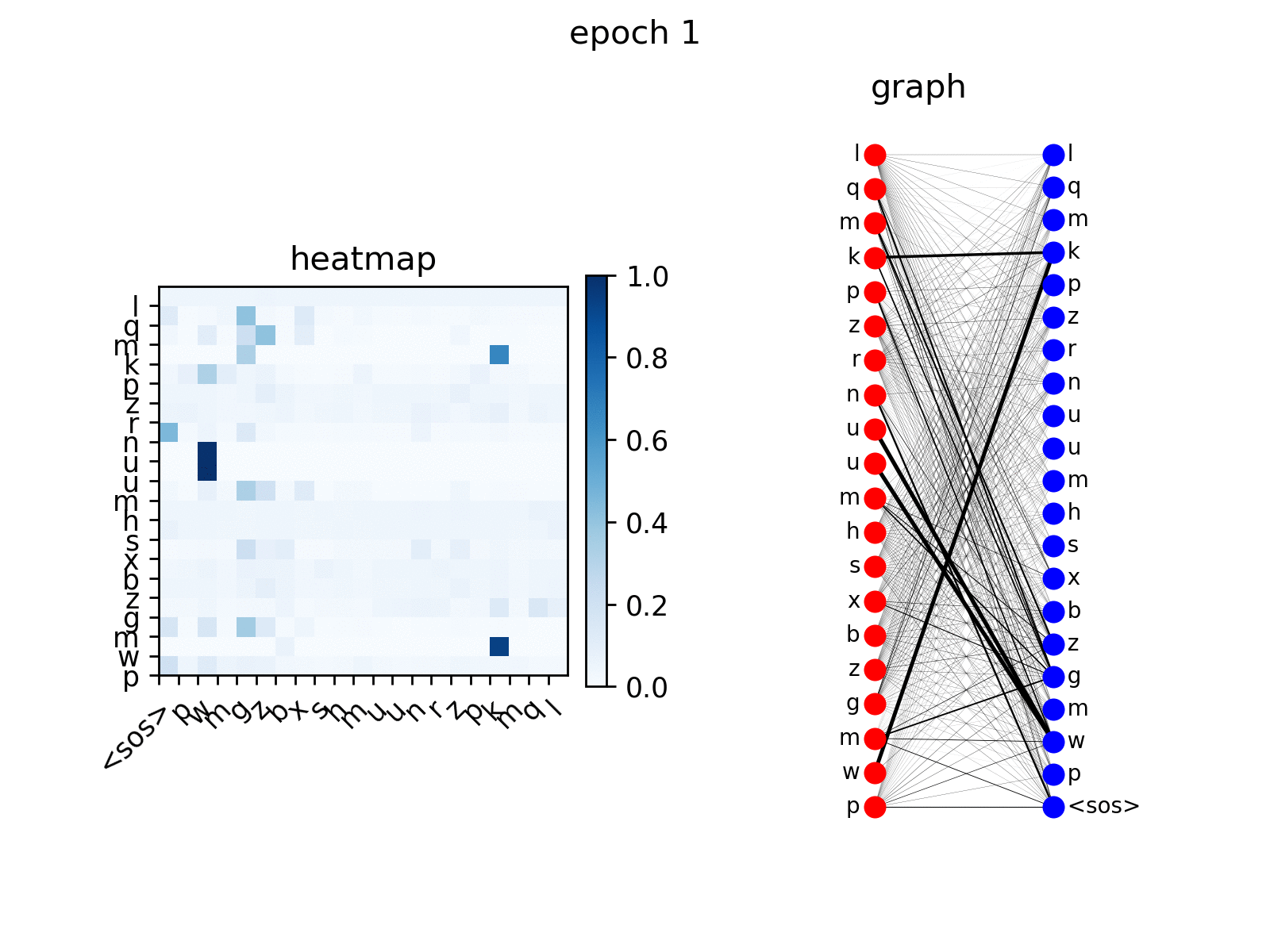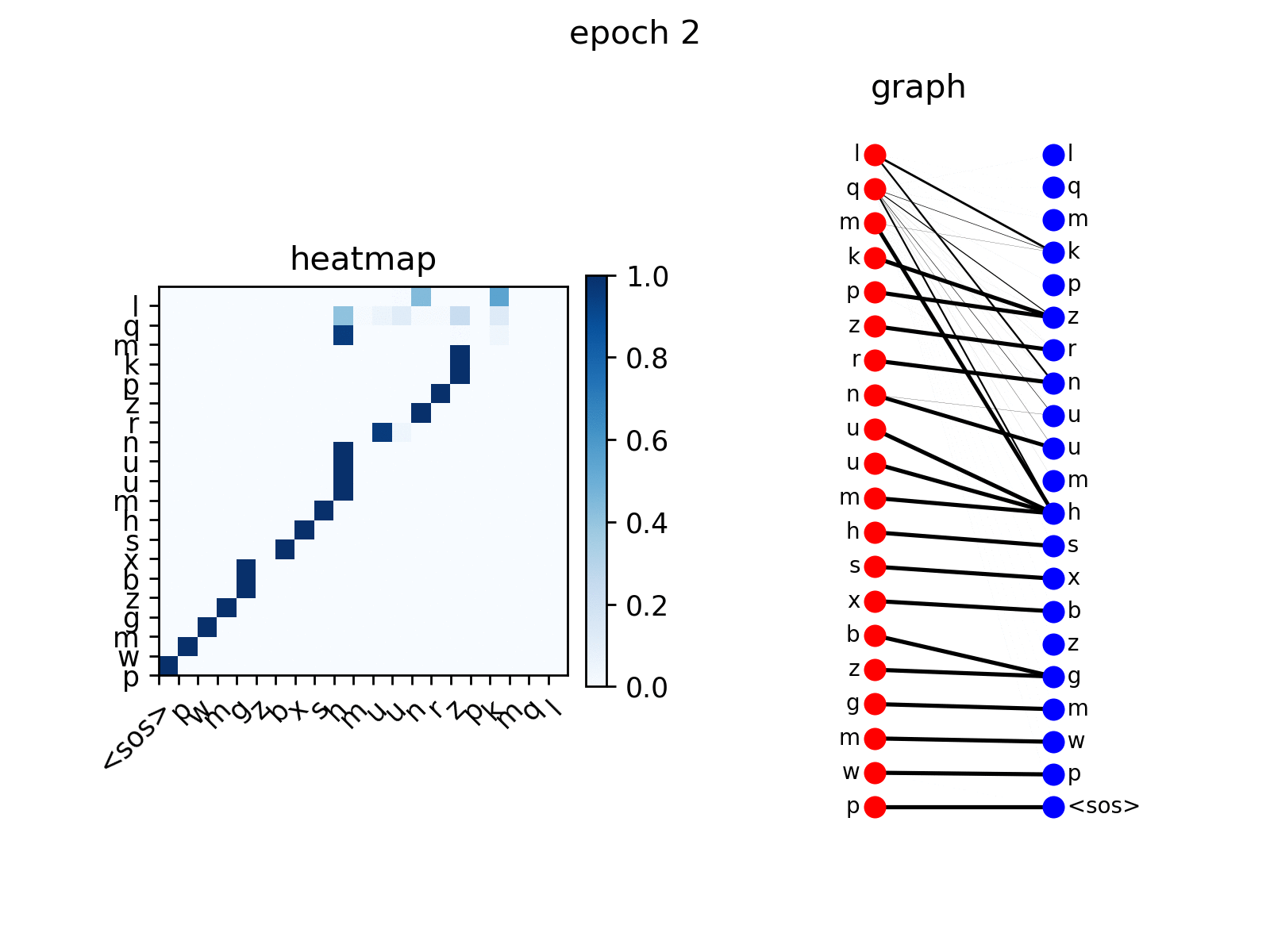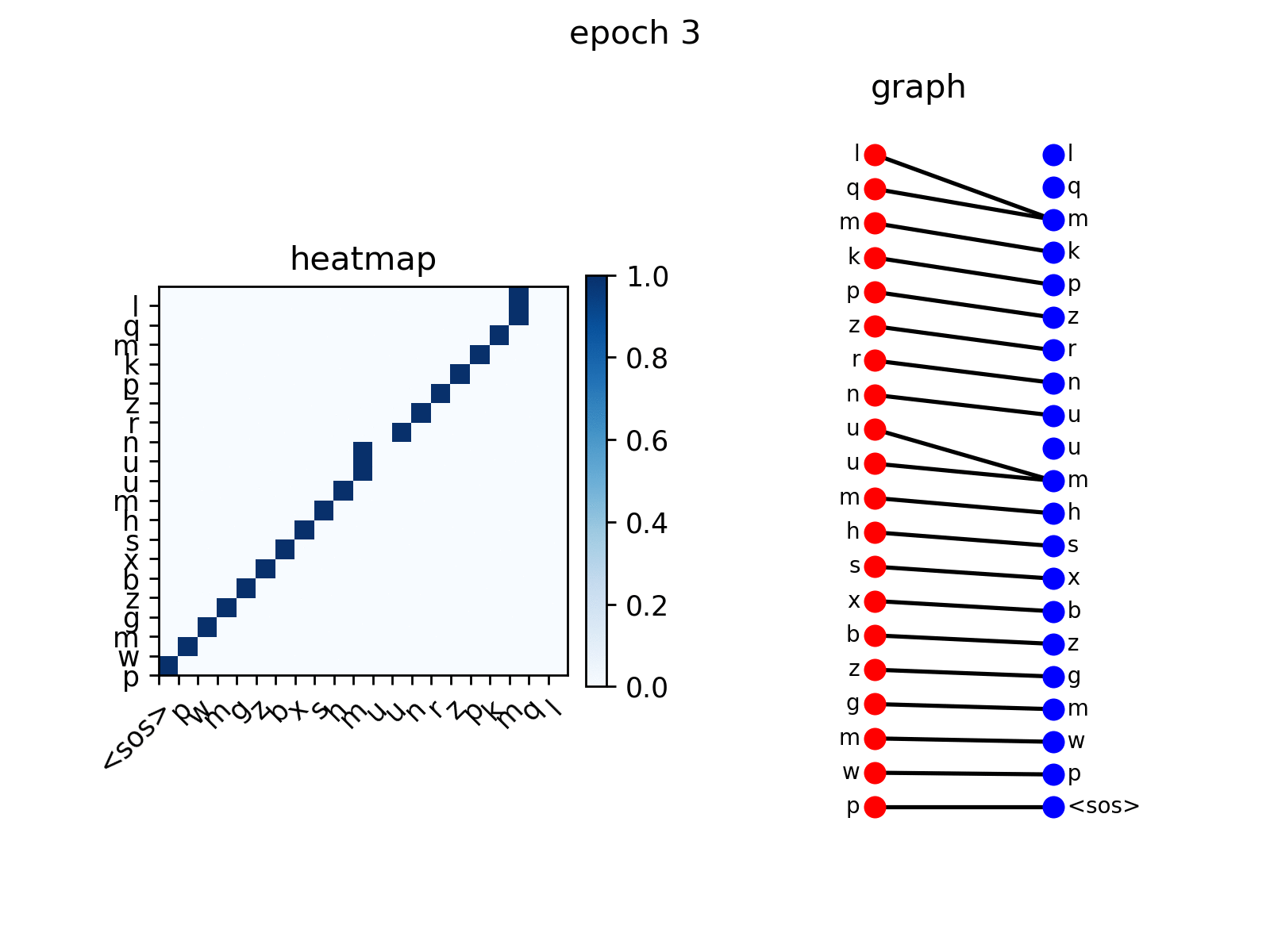
论文笔记:NIPS 2019 Graph Transformer Networks_异质图与异构图CSDN博客
Transformer network baseline for graph datasets for fu-ture research at the intersection of attention and graphs. 2 Proposed Architecture As stated earlier, we take into account two key aspects to develop Graph Transformers - sparsity and positional en-codings which should ideally be used in the best possible way for learning on graph datasets.
A Generalization of Transformer Networks to Graphs Hswyの小窝
A Generalization of Transformer Networks to Graphs. We propose a generalization of transformer neural network architecture for arbitrary graphs. The original transformer was designed for Natural Language Processing (NLP), which operates on fully connected graphs representing all connections between the words in a sequence.

Recipe for a General, Powerful, Scalable Graph Transformer Ladislav
Source code for the paper "A Generalization of Transformer Networks to Graphs" by Vijay Prakash Dwivedi and Xavier Bresson, at AAAI'21 Workshop on Deep Learning on Graphs: Methods and Applications (DLG-AAAI'21).We propose a generalization of transformer neural network architecture for arbitrary graphs: Graph Transformer. Compared to the Standard Transformer, the highlights of the presented.

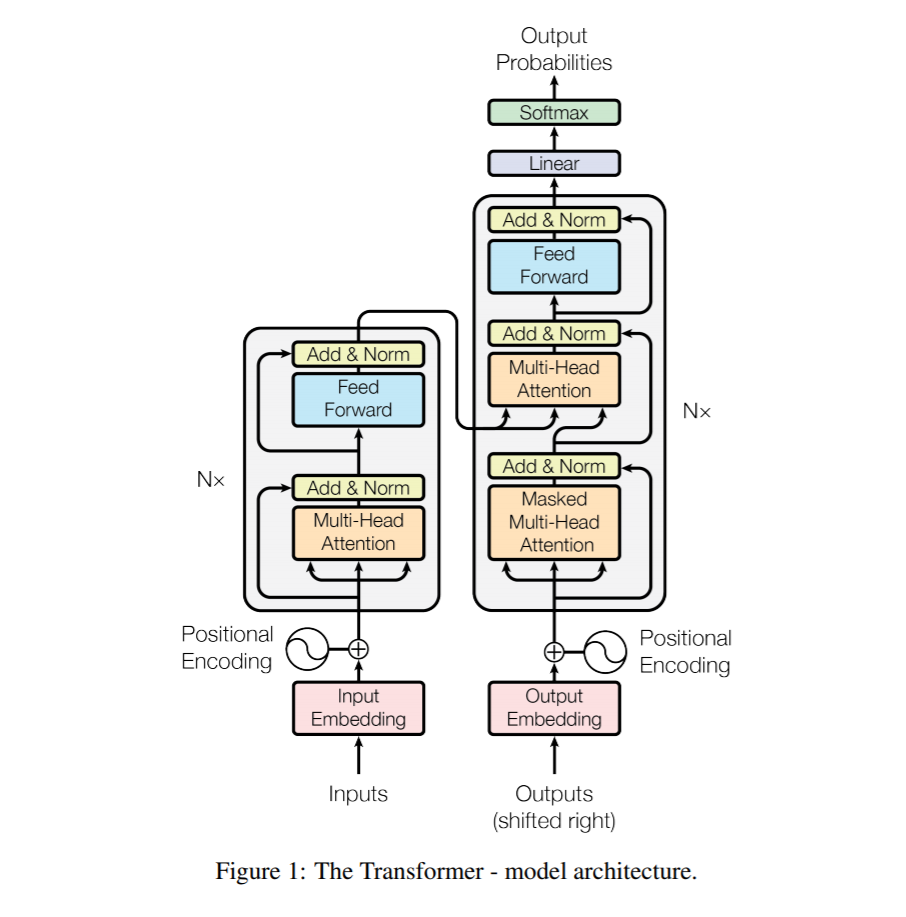
transformer neural network simply explained YouTube
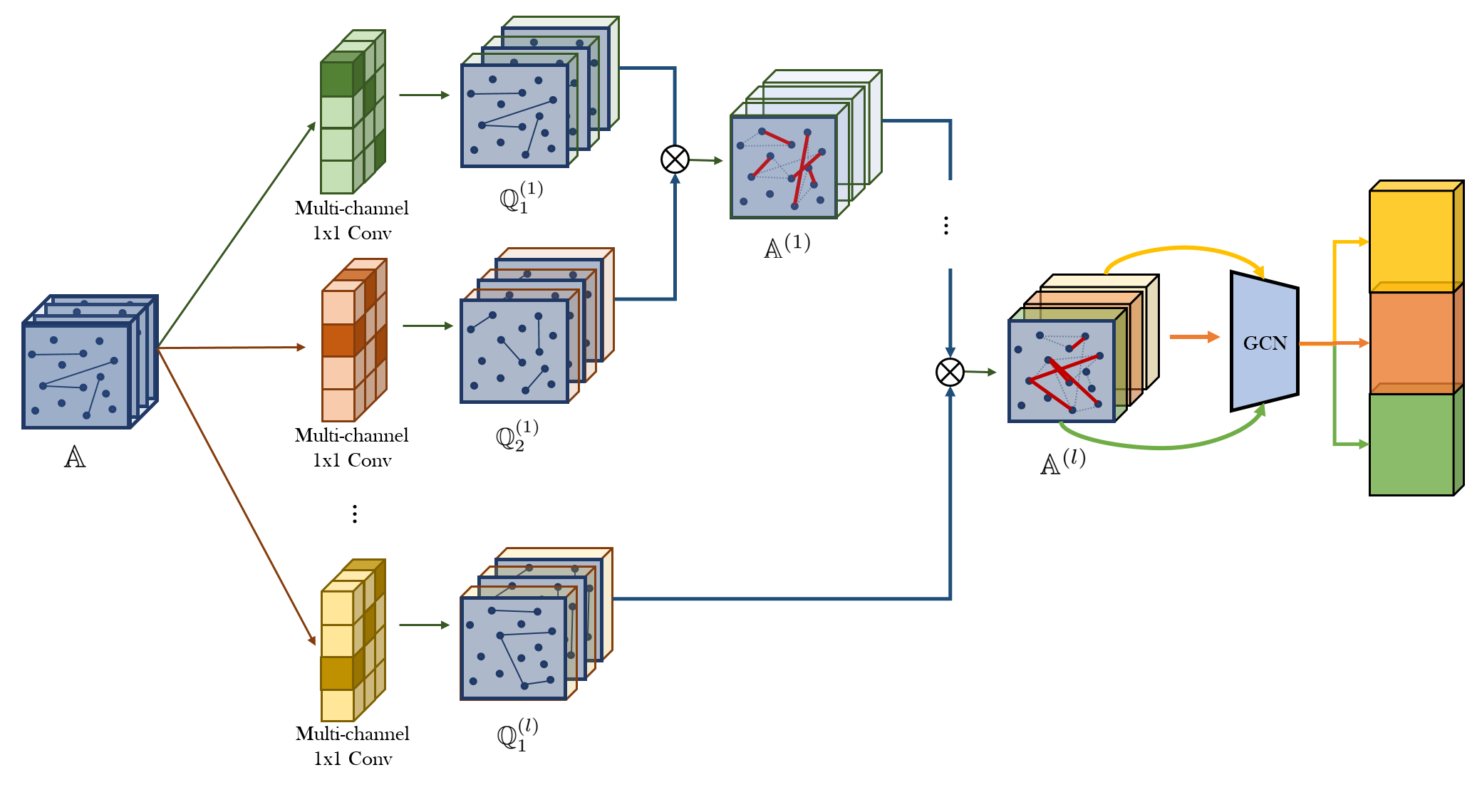
Figure 1: Block Diagram of Graph Transformer with Laplacian Eigvectors (λ) used as positional encoding (LapPE). LapPE is added to input node embeddings before passing the features to the first layer. Left: Graph Transformer operating on node embeddings only to compute attention scores; Right: Graph Transformer with edge features with designated feature pipeline to maintain layer wise edge.
【論文メモ】Graph Transformer A Generalization of Transformer Networks to
1. Background. Lets start with the two keywords, Transformers and Graphs, for a background. Transformers. Transformers [1] based neural networks are the most successful architectures for representation learning in Natural Language Processing (NLP) overcoming the bottlenecks of Recurrent Neural Networks (RNNs) caused by the sequential processing.

A Generalization of Transformer Networks to Graphs Hswyの小窝
A Generalization of Transformer Networks to Graphs . We propose a generalization of transformer neural network architecture for arbitrary graphs. The original transformer was designed for Natural Language Processing (NLP), which operates on fully connected graphs representing all connections between the words in a sequence.
GitHub lsj2408/TransformerM [ICLR 2023] One Transformer Can
We propose a generalization of transformer neural network architecture for arbitrary graphs. The original transformer was designed for Natural Language Processing (NLP), which operates on fully connected graphs representing all connections between the words in a sequence. Such architecture does not leverage the graph connectivity inductive bias, and can perform poorly when the graph topology.
What is Transformer Network Towards Data Science
We propose a generalization of transformer neural network architecture for arbitrary graphs. The original transformer was designed for Natural Language Processing (NLP), which operates on fully connected graphs representing all connections between the words in a sequence. Such architecture does not leverage the graph connectivity inductive bias, and can perform poorly when the graph topology.
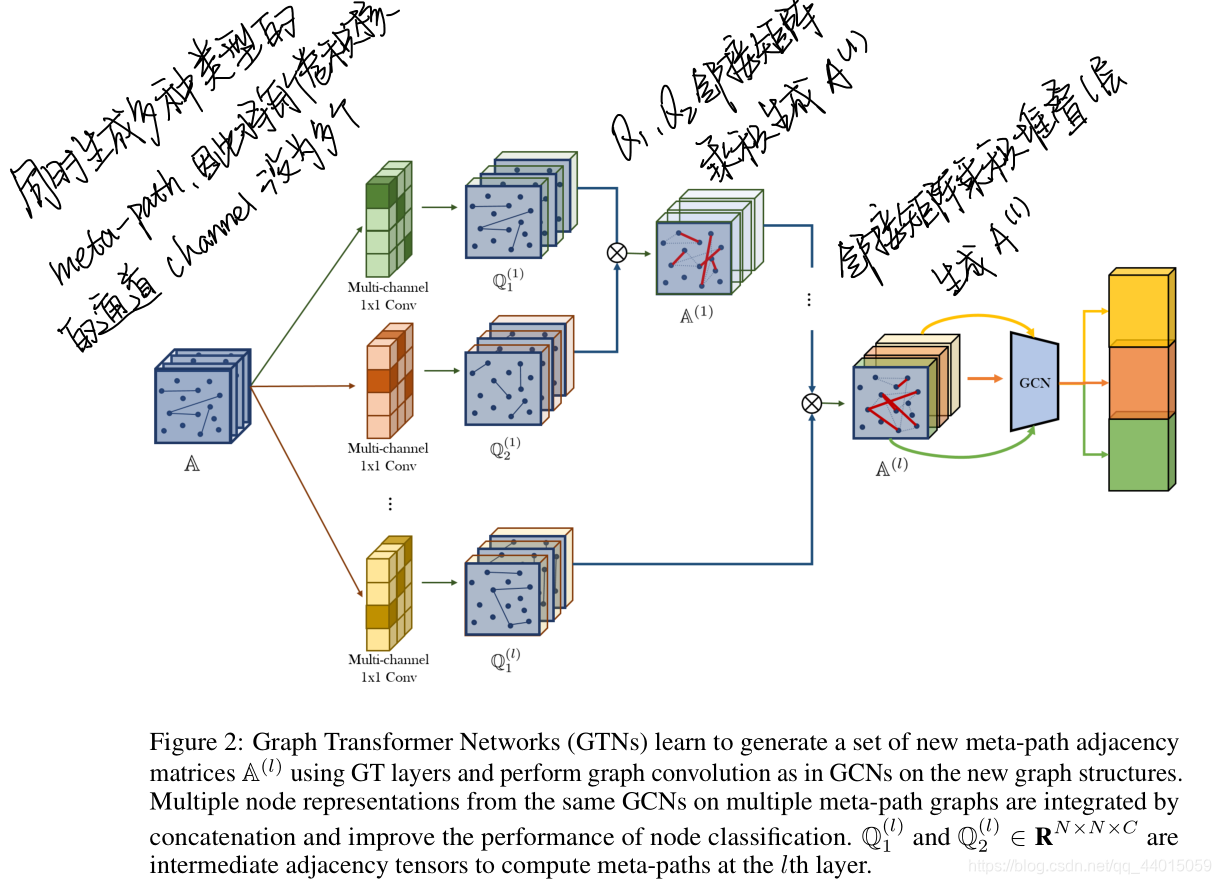
Graph Transformer Networks (GTNs) learn to generate a set of new
We propose a generalization of transformer neural network architecture for arbitrary graphs. The original transformer was designed for Natural Language Processing (NLP), which operates on fully connected graphs representing all connections between the words in a sequence. Such architecture does not leverage the graph connectivity inductive bias.

A Generalization of Transformer Networks to Graphs Hswyの小窝
We propose a generalization of transformer neural network architecture for arbitrary graphs. The original transformer was designed for Natural Language Processing (NLP), which operates on fully connected graphs representing all connections between the words in a sequence. Such architecture does not leverage the graph connectivity inductive bias.

Paper Summary — A Generalization of Transformer Networks to Graphs by
- "A Generalization of Transformer Networks to Graphs" Table 1: Results of GraphTransformer (GT) on all datasets. Performance Measure for ZINC is MAE, for PATTERN and CLUSTER is Acc. Results (higher is better for all except ZINC) are averaged over 4 runs with 4 different seeds.
- A Los Locos Nos Verán Bailando Neon
- Serie De Maggie Y Negan
- Education In Conflict And Post Conflict Zones
- Inscribir Una Escritura En El Registro De La Propiedad
- Hotel El Capricho De Clemente
- Holanda Paseo Por Los Canales El Rio
- Calidades De Algodon Para Polos
- Traje Típico Del Indio Lempira
- Emergencies Operator Site Co Uk
- Disfraz Charlie Y La Fábrica De Chocolate Niño